This was a case where we did randomization without a baseline. I highly recommend this when you’re working with a government because the biggest risk is implementation failure. You’ll spend a lot of time doing the baseline – spend time, spend money – and have the intervention not be implemented. So when you’re working with the government, it’s better to get power by doubling the sample of your endline and just randomized with administrative data so you’ll get the same amount of power but you reduce risk up front.
That is Karthik Muralitharan speaking at the RISE conference today. Of course, he didn’t have to say that doubling your sample also increases your likelihood of randomization resulting in balanced intervention and comparison groups, thus making a baseline less necessary.
Update: This prompted a very active discussion on Twitter, which you can read in full here. Below are a few points.
But wasn’t @singhabhi (and others) just telling us how unreliable admin data are so would this be a problem for comparison. I’m sure I’m missing an obvious point!
— Pauline Rose (@PaulineMRose) June 21, 2018
I would skip the elaborate baseline report, but BL data can be crucial for assessing and correcting for attrition, especially differential attrition. In education (and labor), power advantage with BL data can be huge. BL measures of outcomes can explain 50-70% of final outcome
— Steven Glazerman (@EduGlaze) June 21, 2018
There are other trade offs though. E.g.. rich covariate data is important for (1) assessing external validity and extrapolating well and (2) addressing attrition.
— Cyrus Samii (@cdsamii) June 21, 2018
Having the correct sampling frame also becomes trickier, e.g., kids enrolled in a given school prior to the experiment. Easy to imagine an intervention affecting attendance, dropout, etc.
— Seema Jayachandran (@seema_econ) June 21, 2018
This assumes you have good baseline admin data for all study participants, which isn’t necessarily true. It’s also not true that by not gathering baseline data you’ll save enough $ to double sample. More sample is always good, but this isn’t a magic way to make it affordable.
— Andrew Clarkwest (@AndrewClarkwest) June 21, 2018
Two thoughts on this: If the sample is sufficiently large, then you may not even need to stratify by initial data.
— David Evans (@tukopamoja) June 21, 2018
And I agree that this isn’t magic (and sometimes there’s no way to increase sample). But if it is possible to expand the sample, t’s a good idea to consider where there is significant risk of implementation failure.
— David Evans (@tukopamoja) June 21, 2018
Ultimately, there are a number of factors to consider — the potential sample size, the probability of implementation failure, the importance of baseline covariates for your analysis. But still, where there is serious concern that the program may not be implemented as expected — and especially if there are decent administrative data — it’s worth consideration. I’ll give the penultimate words to Karthik’s co-author, Abhijeet Singh.
First, responding to Pauline and Andrew’s point.
This advice is specific to RCTs: with randomisation, you formally don’t need *any* baseline to estimate average impacts. The key advantages of baseline data – showing balance tables, precision of estimates – are sometimes overwhelmed by risk of non-implementation.
— Abhijeet Singh (@singhabhi) June 21, 2018
Second, to Cyrus and Seema’s points.
Agree with @cdsamii @seema_econ points. Also, care abt heterog by initial levels. So, in researcher/NGO-led interventions, baselines default. When govt implements at scale, major risk that (1) nothing implemented or (2) randomisation not adhered to. (1/3)
— Abhijeet Singh (@singhabhi) June 21, 2018
With baselines often needing 300 schools, very expensive, it’s a margin worth thinking about. The endline will *always* be better targeted to what happened in the program (anecdotally or using admin data). Obviously, ceteris paribus, baseline beats having no baseline 🙂
— Abhijeet Singh (@singhabhi) June 21, 2018
@seema_econ point much harder to deal with. But again, usually (at least in ed), there is some admin data you can retrospectively collect (school enrollment records, official test scores, demographics) which you can figure and bound attrition effects with.
— Abhijeet Singh (@singhabhi) June 21, 2018
And the last word to Karthik himself.
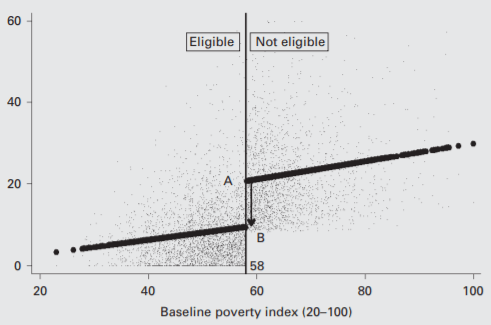
To clarify: Baselines are great (most of my studies have them), but not necessary for an RCT; may even make sense to forego one if funding/teams not in place; or if implementation risk is high. Full discussion in my Handbook Chapter at: https://t.co/XEBFN9KQCk; Key extract below: pic.twitter.com/FUKw0z7qxY
— Karthik Muralidharan (@Prof_Karthik_M) June 22, 2018
There are many more comments, but I won’t embed them all here. You can read the full conversation here on Twitter.